Context is Never Free
Taylor Segell

- Published on

Context Is Never Free
AI in the Wild | Part II
Field notes from real enterprise projects. No theory. Just what actually happened.
You’re six shots into a long AI session, and everything has been going great.
The first few outputs were sharp. Structured. Useful. The model seemed fully locked in. You are moving fast. You are feeling good about the build.
Then six comes back looking suspiciously similar to step three.
The input was completely different.
You reread the prompt. You check whether you pasted the wrong thing. You didn’t. The model just gave you something familiar. Something it had already seen earlier in the session.
Here’s the kicker: the model is not getting lazy.
It is pattern matching against what is most dominant in the context window. And by step six, the loudest thing in the room is often the model’s own earlier output.
This is not a bug.
This is context math.
And understanding it will save you an extraordinary amount of debugging.
Context Competes for Attention
Every AI model has a context window: a finite amount of information it can actively reason over at once.
People often hear that and assume context is always good. More context must mean better answers, right?
Not necessarily.
Context is not passive. It competes for attention.
When your session is short and focused, the model can heavily weight the current task. When the session becomes long and sprawling, your newest prompt has to compete against everything that came before it: previous outputs, previous assumptions, earlier patterns, old constraints, stale requirements, examples that are no longer relevant, and sometimes entire dead branches of thought that should have been buried three hours ago.
Across several enterprise AI and data engineering engagements, I have watched perfectly reasonable prompts produce terrible outputs simply because the surrounding session had become too heavy.
The model was not broken.
It was answering the wrong version of the problem because the context around the problem had drifted.
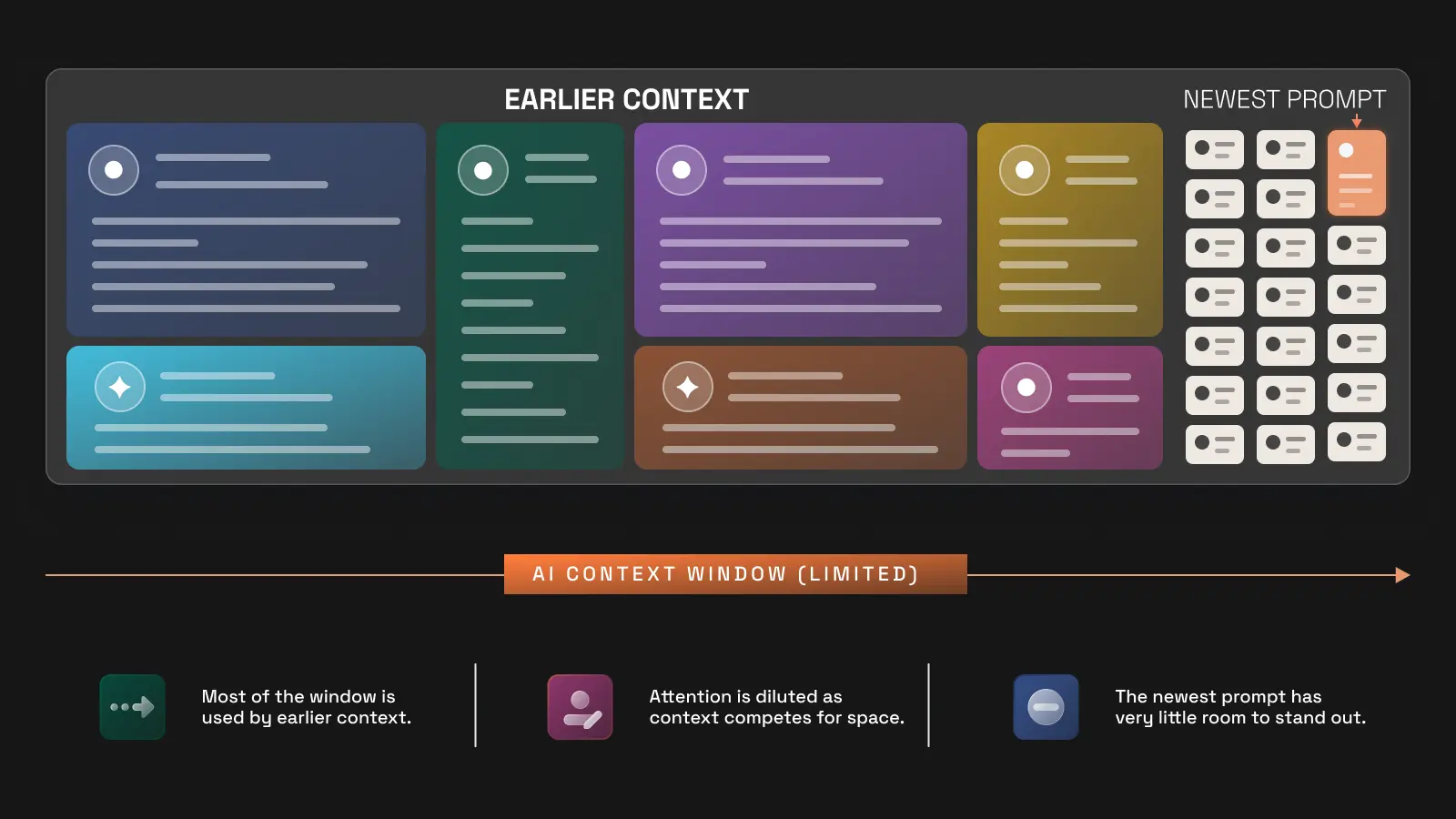
This goes the other direction too. Teams often dump massive amounts of information into prompts upfront because they are afraid the model will “miss something.”
Instead, the model starts padding its response with whatever context appears statistically important. The answer becomes broader, longer, and less useful.
That is what makes bloated context dangerous.
The output looks thoughtful. It sounds comprehensive. It may even feel intelligent.
Meanwhile, the useful answer is buried somewhere around paragraph eleven underneath a pile of AI-generated garnish and emotional support lettuce.
Ouch.
The Three Context Rules
Over time, I ended up following three rules anytime I work with AI systems seriously.
None of them are complicated.
All of them become painfully obvious after you ignore them long enough.
1. Start Fresh More Often Than Feels Necessary
One task. One session.
Not one mega-session covering an entire workflow, pipeline, migration, architecture discussion, debugging cycle, emotional breakdown, and existential reckoning with YAML formatting.
A fresh session gives the model a clean attention budget focused on the current problem. Earlier assumptions do not bleed into the next task. Old outputs stop biasing future outputs.
Without that reset, sessions drift.
Later answers start resembling earlier ones regardless of whether the current input actually warrants it. The model begins stabilizing around its own prior patterns instead of your current intent.
This is especially dangerous in technical workflows because repetition can look like correctness.
The output feels consistent.
But consistency is not the same thing as accuracy.
One of the most effective habits I have seen on strong AI engineering teams is treating sessions like commits.
Finish the task. Write the output to a file. Start clean for the next task.
If you catch yourself typing:
“Continuing from earlier…”
…that is usually your signal to pause and consider whether the session has already exceeded its useful lifespan.
You would not brief an engineer on a complex system once at 8 AM and expect perfect recall at hour seven after forty unrelated discussions.
The model is no different.
2. Scope Your Prompt in Both Directions
Imagine asking a consultant How do I migrate PostgreSQL to Azure SQL?
A good consultant might answer the question.
A great consultant might answer three other questions too.
They might explain migration strategies, discuss organizational change management, compare vendors, outline risks, and provide a twelve-slide roadmap.
All of that is useful. None of it is what you asked for. AI systems behave the same way.
They are rewarded for being helpful, not necessarily concise. That means you NEED to define the boundaries.
Instead of:
Generate a migration plan.
Try:
Create a PostgreSQL-to-Azure SQL migration plan.
Return:
- Numbered steps only
- Maximum 15 steps
- One sentence per step
Do not include:
- Background information
- Architecture explanations
- Risk analysis
- Vendor comparisons
Most people tell the model what they want.
The best users also tell it what to ignore.
3. State Changes Must Be Explicit
The model works from what it has been told, not from what is currently true.
That sounds obvious until you forget to mention that your schema changed three sessions ago, your dependency stack shifted yesterday, or your architecture decision was reversed during a meeting the model was not invited to because, despite the current trajectory of the industry, it still cannot sit in conference rooms and pretend to enjoy stakeholder alignment exercises.
The model does not “notice” environmental changes.
It does not infer organizational decisions.
It does not know your Terraform setup changed because you casually mentioned it halfway through a previous conversation four hours earlier.
It only knows what is currently visible and currently weighted in context.
That means state changes need to be explicit.
One of the highest leverage habits you can build is starting new sessions with a short environment declaration:
- what changed
- what is now true
- what is no longer true
- what constraints now exist
That one paragraph can save hours of debugging.
Without it, the model happily continues optimizing against a world that no longer exists.
Which is how you end up troubleshooting the wrong problem with incredible confidence.
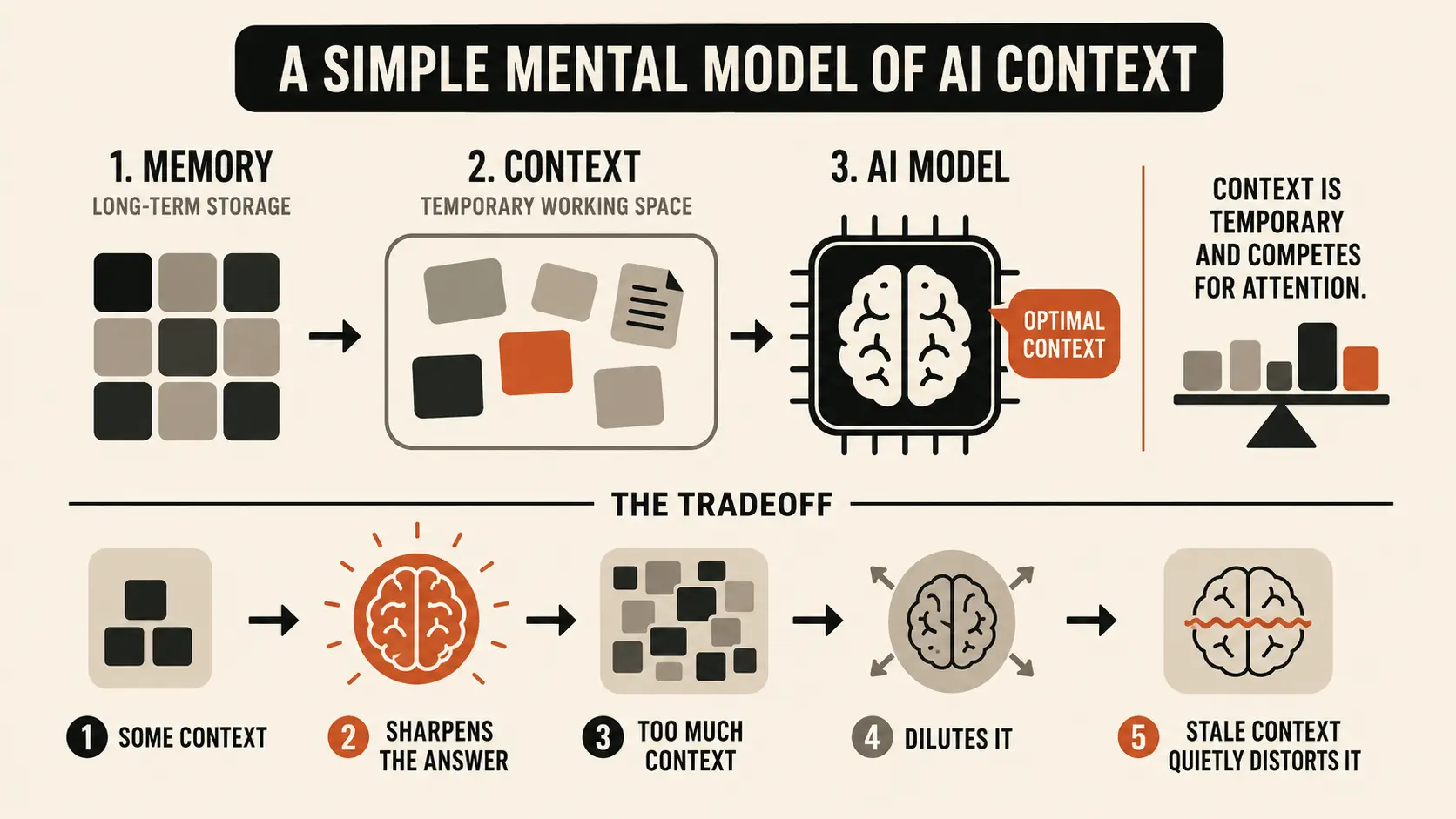
A Simple Mental Model
Context is NOT memory. Context is temporary working space competing for attention.
Every additional piece of information you include is asking the model to care about it. Some context sharpens the answer. Too much context dilutes it. And stale context quietly distorts it.
That is the tradeoff.
Put It Together
A few things worth keeping close:
- Long sessions drift. Fresh sessions focus.
- Context competes for attention.
- Exclusions matter as much as inclusions.
- The model works from what it sees, not from what is true in your environment.
- Stale context produces confident wrong answers, which are significantly more dangerous than obvious failures.
If you do nothing else, do this before your next AI session:
Write one paragraph explaining:
- what you are doing
- what you are not doing
- what changed since last time
You will be shocked how often that alone improves the output quality.
One Thing to Do Today
Before your next AI-assisted task, write two sentences at the top of your prompt:
- What is the task?
- What is explicitly out of scope?
That is it.
Do that consistently for a week and you will start noticing how much output quality was being distorted by context you never intended the model to prioritize.
The AI is a very fast junior engineer.
They do exactly what they understood you to want, not what you meant.
And unfortunately, they start every session on day one.
Stay tuned
Articles, links, and notes on data, AI, and building—roughly weekly in your inbox.